Cluster analysis sui near miss: come trovare pattern dove gli altri vedono solo incidenti
Molte aziende raccolgono near miss.
Poche li leggono davvero.
Il problema non è la mancanza di segnalazioni. Il problema è che quasi sempre ogni near miss viene trattato come un episodio isolato.
Un operatore inciampa su un tubo lasciato a terra. Un carrello sfiora un pedone in area logistica. Un lavoratore segnala un parapetto incompleto. Un manutentore trova una valvola non identificata. Una squadra esegue un’attività fuori sequenza perché il permesso di lavoro non era chiaro.
Cinque eventi. Cinque schede. Cinque azioni correttive. Sembra tutto gestito.
In realtà, sotto potrebbe esserci un unico problema organizzativo: scarsa gestione delle interferenze, layout non leggibile, preposti sovraccarichi, procedure non aderenti al lavoro reale, comunicazione debole tra produzione e manutenzione.
È qui che l’analisi dei near miss deve fare un salto di qualità.
Non basta più chiedersi: “Che cosa è successo?” Serve chiedersi: “A quale famiglia di problemi appartiene questo evento?”
La differenza è enorme. Il singolo near miss ti racconta un fatto. Il gruppo di near miss ti racconta un sistema.

- Cluster analysis sui near miss: come trovare pattern dove gli altri vedono solo incidenti
- Perché i near miss sono dati, non solo segnalazioni
- Il limite dell’analisi tradizionale dei near miss
- Che cos’è la cluster analysis applicata ai near miss
- Il primo errore: analizzare descrizioni scritte male
- La tassonomia: il cuore del metodo
- Come funziona, in pratica, una cluster analysis sui near miss
- Un esempio concreto: tre cluster, tre decisioni diverse
- Near miss e KPI: attenzione a non premiare il silenzio
- Il collegamento con DVR, formazione e audit
- Il metodo operativo per iniziare
- L’errore da evitare: trasformare tutto in statistica e perdere il campo
- Conclusione
Perché i near miss sono dati, non solo segnalazioni
Un near miss — o mancato infortunio — è un evento che avrebbe potuto generare un danno, ma non lo ha prodotto per caso, per intervento tempestivo o per condizioni contingenti favorevoli.
Il punto tecnico è proprio questo: il near miss contiene informazione preventiva. È un segnale debole. Non ha ancora prodotto l’infortunio, non ha generato giorni persi, non è entrato nelle statistiche più visibili — ma mostra che una barriera del sistema si è indebolita.
Il D.Lgs. 81/08 definisce la valutazione dei rischi come una valutazione globale e documentata di tutti i rischi per salute e sicurezza, finalizzata a individuare misure di prevenzione e protezione e a elaborare un programma di miglioramento nel tempo dei livelli di salute e sicurezza. Questo significa che ogni informazione utile a comprendere rischi reali e dinamiche operative deve alimentare il sistema di prevenzione — non restare chiusa in una scheda. I mancati infortuni rientrano tra gli elementi da considerare nell’analisi infortunistica e nella verifica dell’efficacia degli interventi formativi.
Quindi il near miss non è un favore che il lavoratore fa all’azienda quando compila un modulo. È una misura indiretta della qualità del sistema. E, se raccolto bene, diventa una delle fonti più potenti per capire dove il rischio sta crescendo prima che qualcuno si faccia male.
Il limite dell’analisi tradizionale dei near miss
Il modo più comune di analizzare i near miss è ancora troppo semplice. Si contano gli eventi per mese, si dividono per reparto, si classificano per tipologia, si calcola quanti sono stati chiusi, si guarda se il numero aumenta o diminuisce.
Questi dati servono, ma non bastano.
Sapere che a marzo hai avuto 18 near miss e ad aprile 23 può voler dire molte cose diverse: il rischio è aumentato, oppure le persone stanno segnalando di più, oppure è cambiata la sensibilità dei preposti, oppure è stato introdotto un nuovo canale digitale più semplice, oppure un reparto sta vivendo una fase di stress operativo, oppure un appalto ha modificato le interferenze.
Il numero, da solo, non spiega il fenomeno.
Anche l’analisi per categoria può ingannare. Se in un trimestre hai dieci near miss classificati come “inciampo”, potresti pensare di avere un problema di ordine e pulizia. Ma se guardi meglio, potresti scoprire che quegli inciampi avvengono quasi sempre durante attività di manutenzione straordinaria, in aree temporaneamente modificate, con passaggi pedonali deviati, in presenza di imprese esterne e in turni ad alta pressione produttiva.
A quel punto il problema non è “inciampo”. Il problema è gestione del cambiamento operativo.
Questa è la differenza tra contare near miss e analizzare near miss.
Che cos’è la cluster analysis applicata ai near miss
La cluster analysis è una tecnica di analisi dati che raggruppa elementi simili tra loro. Applicata ai near miss, permette di individuare famiglie di eventi che condividono caratteristiche comuni, anche quando a prima vista sembrano diversi.
Non parte da una categoria decisa a tavolino. Parte dai dati.
L’obiettivo non è dire: “Questo evento appartiene alla categoria caduta, questo all’investimento, questo all’elettrico.” L’obiettivo è capire se esistono gruppi ricorrenti di eventi accomunati da variabili operative, organizzative, ambientali o comportamentali.
In pratica, la cluster analysis risponde a domande molto più interessanti: Quali near miss si somigliano davvero? Quali reparti generano eventi con dinamiche analoghe? Quali combinazioni di turno, attività, area e fattore causale ricorrono più spesso? Quali eventi sembrano diversi nella descrizione, ma nascono dallo stesso difetto organizzativo? Quali cluster hanno maggiore potenziale di trasformarsi in infortuni gravi?
Qui l’HSE smette di essere archivista di eventi e diventa analista di sistema.
Il primo errore: analizzare descrizioni scritte male
La cluster analysis funziona solo se i dati sono buoni. E questo è il primo problema.
Molte schede near miss arrivano così: “Situazione pericolosa in reparto.” “Mancato incidente con carrello.” “Operatore non rispettava procedura.” “Materiale lasciato in area.” “Rischio caduta.”
Queste descrizioni non bastano. Sono troppo generiche, troppo soggettive, troppo povere per alimentare un’analisi seria.
Per costruire un metodo solido bisogna trasformare ogni segnalazione in un record strutturato. Un near miss dovrebbe contenere almeno:
- data, ora, reparto o area
- attività in corso e mansione coinvolta
- presenza di appaltatori e fase del lavoro
- energia o pericolo principale
- barriera mancante o inefficace
- fattore contributivo tecnico, organizzativo e umano
- potenziale gravità e probabilità di ripetizione
- azione immediata e azione strutturale
- responsabile del follow-up e tempo di chiusura
Non serve complicare il sistema. Serve renderlo leggibile. Una scheda near miss non deve diventare un romanzo. Deve diventare un dato utilizzabile.
La tassonomia: il cuore del metodo
Il punto più importante non è il software. È la tassonomia.
La tassonomia è il modo in cui decidi di classificare le informazioni. Se è povera, l’analisi sarà povera. Se è pensata bene, anche un semplice Excel può già produrre insight interessanti.
Per un sistema HSE evoluto, la tassonomia dei near miss dovrebbe distinguere almeno cinque livelli.
Il tipo di evento: inciampo, caduta materiale, investimento mancato, contatto elettrico evitato, esposizione chimica potenziale, accesso non autorizzato, uso improprio di attrezzatura, errore di isolamento energia, interferenza tra attività.
Il contesto operativo: produzione ordinaria, manutenzione programmata, manutenzione correttiva, avviamento impianto, fermata, pulizia, carico/scarico, movimentazione, cantiere, emergenza.
Il fattore causale immediato: area ingombra, protezione assente, segnaletica insufficiente, procedura non seguita, attrezzatura non idonea, comunicazione incompleta, permesso di lavoro carente, DPI non disponibile, supervisione assente.
Il fattore organizzativo profondo: pianificazione debole, pressione sui tempi, coordinamento appalti insufficiente, formazione non efficace, layout inadeguato, manutenzione carente, procedura non realistica, carenza di risorse, cambiamento non gestito.
Il potenziale di severità: basso, medio, alto, critico.
Questa struttura consente una lettura completamente diversa. Non stai più dicendo “abbiamo avuto 12 near miss su ordine e pulizia”. Stai dicendo: “Il 60% dei near miss ad alto potenziale si concentra durante manutenzioni correttive in aree con interferenza tra personale interno e ditte esterne, con fattore organizzativo ricorrente legato alla pianificazione del lavoro.”
Questa frase cambia completamente la qualità della decisione.
Come funziona, in pratica, una cluster analysis sui near miss
Il metodo si articola in fasi precise e puoi applicarlo anche senza strumenti complessi.
Nella prima fase raccogli ogni near miss con campi standard. Il testo libero resta utile, ma non può essere l’unica fonte. Servono variabili codificate.
Nella seconda fase pulisci i dati: elimina duplicati, correggi classificazioni incoerenti, uniforma nomi di reparti, mansioni, imprese, aree e tipologie di evento. Se un reparto viene scritto in quattro modi diversi, per il sistema sono quattro reparti diversi.
Nella terza fase codifichi le descrizioni qualitative in variabili analizzabili. Ad esempio, “il carrellista ha sterzato all’ultimo per evitare un operaio” diventa: evento = investimento mancato; area = logistica; attività = movimentazione; soggetto = carrello/pedone; barriera fallita = separazione percorsi; fattore organizzativo = layout/interferenza; potenziale = alto.
Nella quarta fase scegli le variabili rilevanti. Per una prima analisi bastano area, attività, tipo evento, barriera fallita, fattore organizzativo, potenziale gravità e presenza di appaltatori.
Nella quinta fase raggruppi. In una PMI può bastare una matrice pivot evoluta, incrociando variabili e cercando combinazioni ricorrenti. In contesti più maturi puoi usare algoritmi di clustering veri e propri, come il clustering gerarchico, il k-modes per variabili categoriali o il k-prototypes quando hai variabili miste.
Nella sesta fase, quella più delicata, interpreti. Il software raggruppa eventi simili. Ma serve competenza HSE per capire cosa significa quel gruppo. Un cluster non è una sentenza. È un indizio tecnico.
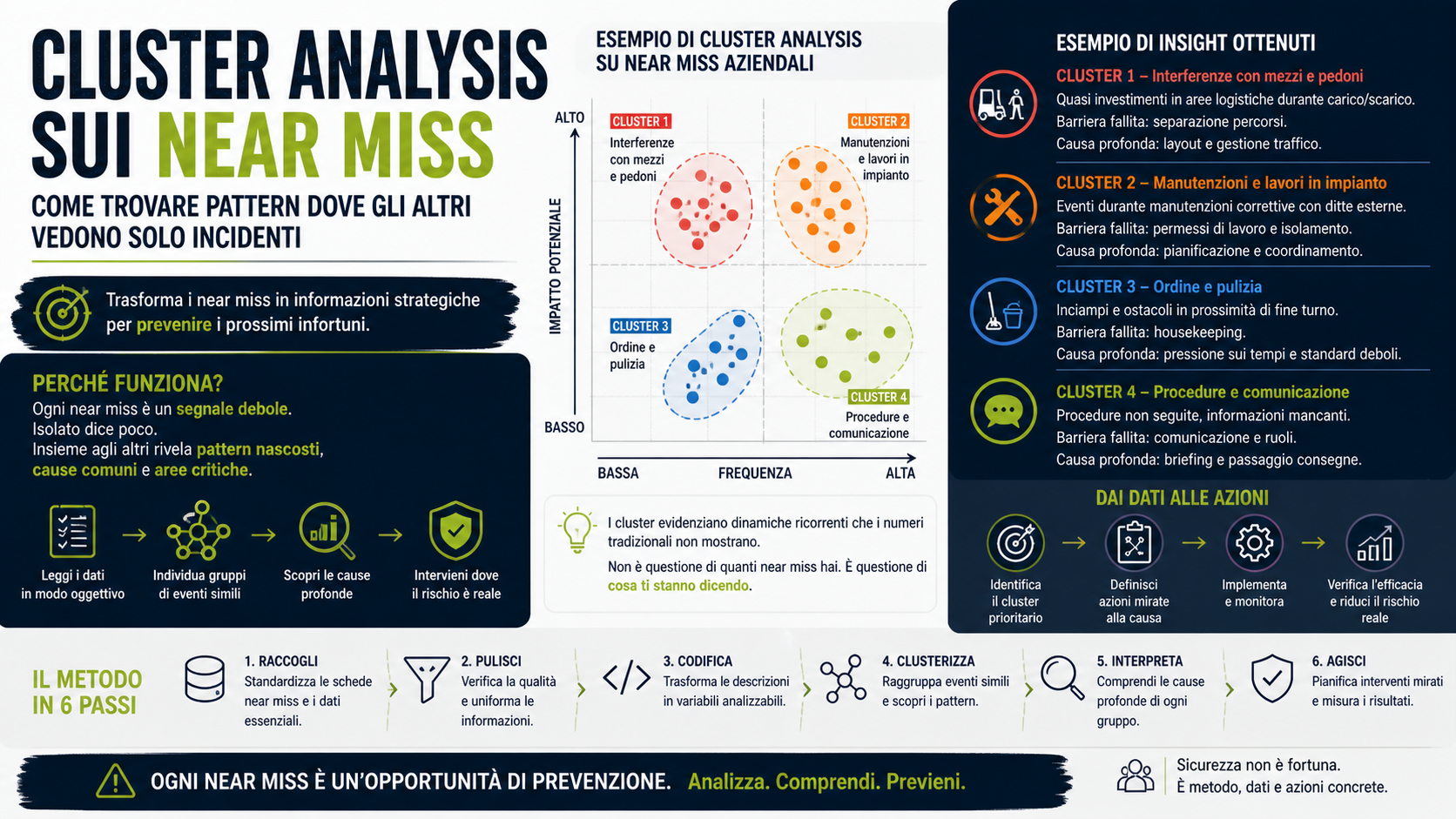
Un esempio concreto: tre cluster, tre decisioni diverse
Immagina un’azienda industriale con 85 near miss raccolti in sei mesi.
L’analisi tradizionale dice: molti eventi in logistica, diversi casi di inciampo, alcune segnalazioni su appaltatori, aumento delle segnalazioni nei mesi di aprile e maggio. Informazione utile, ma ancora generica.
Con una cluster analysis emergono tre gruppi distinti.
Il primo cluster raccoglie eventi di quasi investimento tra carrelli e pedoni, concentrati in fascia mattutina, durante carico e scarico, in due aree specifiche. La barriera ricorrente fallita è la separazione dei percorsi. Il fattore organizzativo è il layout. Qui l’azione non è fare un corso generico sui carrelli: serve riprogettare flussi, segnaletica, attraversamenti, specchi, velocità, varchi, gestione delle baie e regole di priorità.
Il secondo cluster raccoglie near miss legati a manutenzioni correttive, con imprese esterne, in presenza di permessi di lavoro incompleti o non aggiornati. Gli eventi sembrano diversi — accesso in area non segregata, attrezzatura non isolata, interferenza con attività produttiva, mancata comunicazione al capo turno — ma il cluster dice una cosa precisa: il problema non è il singolo comportamento. È la gestione operativa dell’intervento. L’azione deve riguardare permessi di lavoro, coordinamento, ruoli, briefing pre-attività, lockout/tagout, verifica di campo prima dell’avvio.
Il terzo cluster raccoglie segnalazioni apparentemente minori: inciampi, materiale fuori posto, passaggi ostruiti, attrezzature temporanee lasciate in area. Tutte avvengono in prossimità di fine turno o durante picchi produttivi. Il tema potrebbe sembrare housekeeping, ma la causa profonda può essere un’altra: pressione sui tempi, mancanza di standard di ripristino, passaggio consegne debole.
Tre cluster. Tre famiglie di rischio. Tre strategie diverse.
Senza cluster analysis, l’azienda avrebbe probabilmente prodotto tre azioni deboli: richiamo al personale, comunicazione interna, aggiornamento procedura. Con la cluster analysis, l’azienda interviene sul sistema.
Near miss e KPI: attenzione a non premiare il silenzio
Uno degli errori più gravi è usare il numero di near miss come indicatore “da ridurre” senza interpretazione.
Se comunichi ai reparti che devono diminuire i near miss, potresti ottenere un effetto pessimo: le persone smettono di segnalare.
Un aumento dei near miss non è sempre negativo. Può indicare maggiore fiducia nel sistema, maggiore presenza dei preposti in campo, una campagna di sensibilizzazione riuscita, un’organizzazione che finalmente vede problemi prima ignorati.
Per questo i KPI devono essere costruiti bene. Ha senso misurare la percentuale di near miss gestiti rispetto al totale, perché indica la capacità dell’organizzazione di rilevare e gestire preventivamente eventi che potrebbero trasformarsi in incidenti gravi. Ha senso misurare il coinvolgimento dei lavoratori nelle segnalazioni, perché un sistema con molti eventi segnalati da poche persone non è maturo: è dipendente da pochi soggetti attivi.
Ma il KPI più importante non è “quanti near miss abbiamo avuto”. È: “Che cosa abbiamo capito dai near miss?”
Il collegamento con DVR, formazione e audit
L’analisi cluster dei near miss non deve restare dentro un report HSE separato. Deve entrare nel DVR, nella formazione, negli audit interni e nella pianificazione delle azioni di miglioramento.
Se un cluster evidenzia che molti eventi riguardano interferenze tra appaltatori e personale interno, quel dato deve interrogare la gestione degli appalti, i DUVRI, i permessi di lavoro e le riunioni di coordinamento. Se un cluster evidenzia errori ricorrenti nell’uso di una macchina, quel dato deve interrogare addestramento, istruzioni operative, manutenzione, ergonomia, interfaccia uomo-macchina e vigilanza del preposto. Se un cluster mostra eventi concentrati in un turno specifico, non basta dire che “quel turno lavora male”: bisogna capire carichi, supervisione, esperienza media, pressione produttiva, composizione della squadra, passaggio consegne.
Le procedure standardizzate per la valutazione dei rischi richiamano la necessità di valutare i pericoli e definire un programma di miglioramento, utilizzando metodiche adeguate alle situazioni aziendali e criteri basati sull’esperienza, sulle condizioni effettive e su dati come le dinamiche infortunistiche. I near miss entrano perfettamente in questa logica: sono dati sulle condizioni effettive.
Il metodo operativo per iniziare
Una PMI non deve partire con algoritmi complessi. Può iniziare con un metodo molto concreto, costruito per passi.
Prima: definisci una scheda near miss con campi obbligatori chiari. Seconda: costruisci una tassonomia semplice ma stabile. Terza: forma preposti e lavoratori su cosa segnalare e come descriverlo. Quarta: valida ogni segnalazione con una breve analisi HSE. Quinta: assegna un potenziale di severità, non solo una categoria. Sesta: fai una revisione mensile dei cluster ricorrenti. Settima: collega ogni cluster a un’azione organizzativa, non solo correttiva. Ottava: verifica dopo tre o sei mesi se quel cluster si riduce, cambia forma o si sposta altrove.
Quest’ultimo punto è decisivo. Un rischio non sempre scompare — a volte migra. Modifichi un layout e diminuiscono i quasi investimenti in un’area, ma aumentano in un’altra. Introduci una procedura più rigida e diminuiscono gli errori formali, ma aumentano le scorciatoie operative. Fai formazione su un rischio e aumentano le segnalazioni perché le persone ora lo riconoscono meglio. Senza lettura sistemica, questi segnali vengono interpretati male.
L’errore da evitare: trasformare tutto in statistica e perdere il campo
La cluster analysis non sostituisce il sopralluogo. Non sostituisce il confronto con i lavoratori. Non sostituisce il ruolo dei preposti. Non sostituisce l’esperienza tecnica dell’HSE.
La potenzia.
Il dato ti dice dove guardare. Il campo ti dice perché succede.
Se un cluster mostra che molti near miss avvengono in una determinata area, devi andarci. Devi osservare flussi, spazi, rumore, illuminazione, interferenze, posture, tempi, comunicazioni, pressioni.
La sicurezza non si fa davanti a una dashboard. La dashboard serve a decidere dove mettere gli occhi.
Conclusione
Il valore dei near miss non sta nel numero di schede raccolte. Sta nella capacità di trasformare quelle schede in conoscenza operativa.
Una segnalazione isolata può sembrare piccola. Dieci segnalazioni simili diventano un pattern. Un pattern ricorrente diventa un’informazione gestionale. Un’informazione gestionale, letta bene, diventa prevenzione.
La cluster analysis sui near miss serve esattamente a questo: vedere connessioni dove gli altri vedono episodi. Non è un esercizio statistico fine a sé stesso. È un modo più maturo di fare sicurezza.
Perché l’infortunio spesso sembra improvviso solo a chi non ha letto i segnali precedenti. I near miss quei segnali li avevano già dati. La domanda è se l’azienda aveva un metodo per ascoltarli.
Rispondi